Ten artykuł nie jest skończony. Możesz pomóc w jego ukończeniu edytując tą stronę.
Funkcje
W tej lekcji dowiesz się jak nauczyć program wykonywania akcji, z możliwością ich wielokrotnego użytku.
Motywacja
Jednym z plusów używania funkcji jest redukcja potwórzeń w kodzie. Zobacz przykład poniżej, w wersji bez użycia funkcji oraz z użyciem. Na ten moment nie musisz rozumieć zapisu z przykładu z funkcją - do wyjaśnienia przejdziemy w dalszej części tej lekcji.
- ⚠ Bez funkcji
- 🟢 Z funkcją
#include <iostream>
#include <vector>
int main()
{
std::vector<int> numbers = {1, 4, 13, 15};
for (int i : numbers) {
std::cout << i << ' ';
}
std::cout << '\n';
numbers.push_back(13);
for (int i : numbers) {
std::cout << i << ' ';
}
std::cout << '\n';
numbers.push_front(3);
for (int i : numbers) {
std::cout << i << ' ';
}
std::cout << '\n';
}
#include <iostream>
#include <vector>
void print(std::vector<int> vec)
{
for (int i : vec) {
std::cout << i << ' ';
}
std::cout << '\n';
}
int main()
{
std::vector<int> numbers = {1, 4, 13, 15};
print(numbers);
numbers.push_back(13);
print(numbers);
numbers.push_front(3);
print(numbers);
}
W przykładzie powyżej tworzymy tablicę liczb i modyfikujemy ją, każdorazowo wyświetlając zawartość. Różnica między tymi dwoma wersjami jest taka, że pierwszy zawiera fragment kodu, który przekleiliśmy parę razy komendą kopiuj-wklej. W drugiej, bardziej prawidłowej wersji, jednorazowo uczymy nasz program jak wyświetlić tablicę liczb a następnie korzystamy z tego wielokrotnie wtedy, kiedy tego potrzebujemy.
Funkcje mają jeszcze bardzo wiele innych zastosowań i część z nich w tej lekcji pokażemy. Póki co jednak musimy powrócić na sam początek do podstaw.
Wprowadzenie
Funkcja to wydzielony fragment kodu, który możemy wielokrotnie wykorzystywać.
Od samego początku nauki w naszych programach umieszczaliśmy specjalną funkcję,
którą jest main.
int main() {
// kod programu
}
Komputer uruchamiając program znajduje funkcję main a następnie ją wykonuje,
przechodząc po każdej instrukcji wewnątrz, linijka po linijce.
Tworzenie funkcji
Zaczniemy od najprostszych funkcji, stopniowo przechodząc do coraz bardziej zaawansowanych.
Bez parametrów
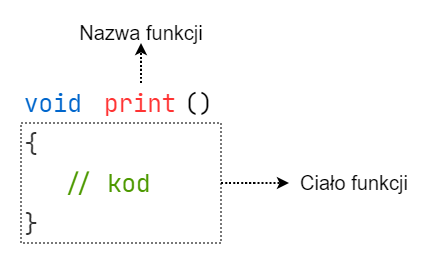
Jak widzimy wyżej, definiując własną funkcję, musimy zadbać o jej nazwę oraz ciało, trzymając
się przy tym składni. Po słowie void piszemy nazwę funkcji, następnie dajemy puste
nawiasy okrągłe (o tym powiemy dalej w tej lekcji), potem bez średnika umieszczamy poniżej
blok kodu, który nazywamy ciałem funkcji.
Nazywając funkcję przestrzegamy tych samych zasad co przy nazwach zmiennych.
W ten sposób mamy już zdefiniowaną funkcję. Oznacza to, że gdy tylko będziemy tego chcieli, możemy ją wywołać. Robimy to w ten sposób:
print();
Zwróć uwagę, że umieściliśmy średnik po wywołaniu funkcji, bo jest to też koniec instrukcji.
Napiszmy przykładową funkcję, która wyświetla 10 liczb parzystych i użyjmy jej kilka razy:
#include <iostream>
// Definicja funkcji
void print_10_even_numbers()
{
for (int i = 0; i < 10; i++)
std::cout << (i * 2) << ' ';
std::cout << '\n';
}
int main()
{
// Wywołanie funkcji
print_10_even_numbers();
print_10_even_numbers();
print_10_even_numbers();
}
0 2 4 6 8 10 12 14 16 18
0 2 4 6 8 10 12 14 16 18
0 2 4 6 8 10 12 14 16 18
Z parametrami
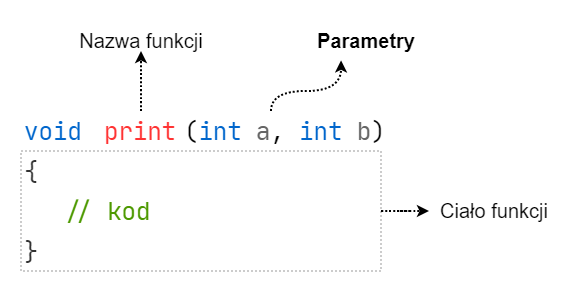
Działanie funkcji możemy uzależnić od parametrów. Chcąc, żeby funkcja wyświetlała dowolnie dużo liczb parzystych, możemy utworzyć w funkcji parametr, który będzie to kontrolował. Parametr jest zmienną wewnątrz funkcji, którą tworzymy w środku nawiasów okrągłych:
#include <iostream>
void print_even_numbers(int how_many)
{
for (int i = 0; i < how_many; i++)
std::cout << (i * 2) << ' ';
std::cout << '\n';
}
int main()
{
print_even_numbers(10);
print_even_numbers(5);
print_even_numbers(3);
}
Powyższy zapis
print_even_numbers(10);
oznacza, że w momencie wywołania, do parametru how_many wewnątrz tej funkcji
zostanie przypisana wartość 10. Możemy do funkcji przekazywać dowolną liczbę parametrów.
Oddzielamy je przecinkami:
#include <iostream>
void print_bigger_number(int a, int b)
{
if (a > b)
std::cout << a << '\n';
else
std::cout << b << '\n';
}
int main() {
print_bigger_number(3, 5);
print_bigger_number(5, 3);
print_bigger_number(3, 10);
}
Zauważ, że kolejne parametry funkcji umieszczamy po przecinku, każdorazowo podając jego typ. Częstym błędem wśród początkujących jest pominięcie typu w następnych parametrach.
- ❌ Źle
- ✔ Dobrze
void print_bigger_number(int a, b)
void print_bigger_number(int a, int b)
Instrukcja powrotu
Możemy kazać programowi wcześniej powrócić z funkcji, za pomocą instrukcji:
return;
W momencie jej napotkania, program przestaje wykonywać kolejne instrukcje w funkcji
i wraca do miejsca, z którego została ona wywołana. Przytoczmy stworzoną przez nas wcześniej
funkcję print_even_numbers:
void print_even_numbers(int how_many)
{
for (int i = 0; i < how_many; i++)
std::cout << (i * 2) << ' ';
std::cout << '\n';
}
Co się stanie, jeśli podamy ujemną liczbę do how_many?
print_even_numbers(-10);
Wykonywanie funkcji z taką wartością parametru nie ma sensu, dlatego możemy to już na samym początku wychwycić i wykonać powrót:
void print_even_numbers(int how_many)
{
if (how_many <= 0)
return;
for (int i = 0; i < how_many; i++)
std::cout << (i * 2) << ' ';
std::cout << '\n';
}
Teraz gdy podamy wartość mniejszą lub równą zero do parametru funkcji, funkcja już na początku zostanie przerwana.
Wartość zwracana
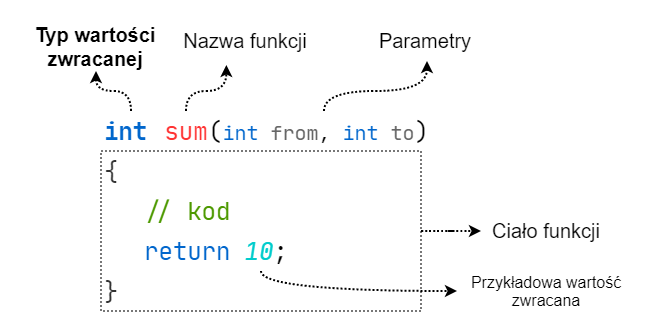
Funkcje mogą pozostawić po swoim wykonaniu pewien rezultat. Łatwiej będzie to zrozumieć gdy zastosujemy analogię do realnego życia. Rodzic wysyła swoje dziecko do sklepu po 10 jajek. Po powrocie dziecka, będzie chciał wiedzieć, czy udało mu się kupić tyle ile poprosił, czy nie. Tak samo my, wykonując niektóre funkcje w kodzie, chcemy znać ich rezultat, czyli wartość zwracaną.
Typ zwracanej wartości
Wymagane jest, aby określić jakiego typu jest wartość zwracana. Podajemy go przed nazwą funkcji, przykładowo:
int sum(int from, int to)
void print(int number)
Zauważ, że wprowadziliśmy nowy typ: void (z ang.: pusty). Jeśli wpiszemy go w miejsce typu zwracanego,
będzie to oznaczało, że funkcja nie zwraca wartości, tj. nie potrzebujemy znać jej rezultatu.
Zauważ, że z void korzystaliśmy w poprzednich sekcjach tej lekcji, właśnie z tego powodu.
Typ void nie może być użyty do stworzenia zmiennej:
void variable;
Zmienna z założenia przechowuje wartość, co byłoby niemożliwe gdyby była typu void.
Zastosowanie
Zaimplementujmy funkcję ze schematu wyżej. Ma ona zliczyć sumę wszystkich liczb w zakresie od from do to włącznie.
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
Zwróconą wartość możemy użyć np. zapisując ją do zmiennej:
int s = sum(10, 100);
... lub użyć w wyrażeniu (np. jako parametr funkcji):
std::cout << "Suma liczb z zakresu [10; 100] wynosi: " << sum(10, 100);
Wymogi
Funkcja, która zwraca jakąś wartość (wszystko poza typem void), musi na samym końcu swojego wykonania
zwrócić jakąś wartość.
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
// ❌ Brak instrukcji return!
}
Wyjątkiem jest funkcja main, która mimo zwracania typu int, wykonuje automatyczne zwrócenie wartości
gdy pominiemy return:
int main() {
// Brak instrukcji return
}
O funkcji main powiemy więcej w przyszłości.
Deklaracja a definicja
Aby móc użyć powyższej funkcji sum, musimy upewnić się, że znajduje się ona przed tym użyciem, przykładowo:
- ❌ Źle
- ✔ Dobrze
#include <iostream>
int main()
{
// Błąd: użycie przed definicją
std::cout << "Suma liczb z zakresu [10; 100] wynosi: " << sum(10, 100);
}
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
#include <iostream>
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
int main()
{
std::cout << "Suma liczb z zakresu [10; 100] wynosi: " << sum(10, 100);
}
Dbanie o to, żeby kolejność zawsze się zgadzała jest uciążliwe a czasami nawet niemożliwe. Żeby naprawić błąd z powyższego przykładu musimy zastosować tzw. deklarację funkcji.
Póki co tworząc funkcję, używaliśmy definicję funkcji, która oprócz deklaracji, zawiera też całą jej implementację (ciało). Deklarowanie funkcji wygląda jak jej definiowanie, bez podawania jej ciała. Musimy też zadbać, żeby po deklaracji dać średnik.
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
int sum(int from, int to);
Zasada jest taka, że aby użyć funkcji, musi być ona wcześniej zadeklarowana. Definicja musi się pojawić, jednak nie ma znaczenia czy będzie ona przed czy po użyciu. Oto dwa przykłady:
- ✔ OK
- ✔ OK (definicja przed)
- ✔ OK (wiele dekl.)
#include <iostream>
// 🟣 Deklaracja
int sum(int from, int to);
int main()
{
std::cout << "Suma liczb z zakresu [10; 100] wynosi: " << sum(10, 100);
}
// 🔵 Definicja
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
#include <iostream>
// 🟣 Deklaracja
int sum(int from, int to);
// 🔵 Definicja
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
int main()
{
std::cout << "Suma liczb z zakresu [10; 100] wynosi: " << sum(10, 100);
}
#include <iostream>
// 🟣 Deklaracje
int sum(int from, int to);
int sum(int from, int to); // OK, wiele deklaracji dopuszczalne
int sum(int from, int to); // tylko po co to tutaj? 🤔
int main()
{
std::cout << "Suma liczb z zakresu [10; 100] wynosi: " << sum(10, 100);
}
// 🔵 Definicja
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
Definicja musi pojawić się w kodzie tylko raz (deklaracji może być wiele).
Przykłady 🚧
Ta sekcja wymaga rozbudowy. Możesz nam pomóc edytując tą stronę.
Potencjalne błędy
Brak widocznej deklaracji
Jednym z bardzo często popełnianych błędów jest próba użycia funkcji, bez jej deklaracji:
- ❌ Źle
- ✔ Dobrze
- ✔ Również dobrze
#include <iostream>
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
Kompilator musi wiedzieć, że funkcja istnieje jeszcze przed jej użyciem (konkretniej - musi znać jej typ zwracany, nazwę oraz typy parametrów).
🔴 Treść błędu



#include <iostream>
int sum(int from, int to);
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
#include <iostream>
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
Brak widocznej definicji
Kolejnym bardzo często spotykanym błędem jest zadeklarowanie funkcji i niedostarczenie jej definicji. W takim wypadku dostaniemy błąd linkera, nie kompilatora.
#include <iostream>
int sum(int from, int to);
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
🔴 Treść błędu
- CLANG
- GCC
- MSVC



Różnica pomiędzy kompilatorem a linkerem jest taka, że kompilator tylko i wyłącznie bierze nasz kod i zamienia kod w pliki obiektowe,
która są niczym innym niż kodem zrozumiałym przez nasz komputer.
Na plikach obiektowych się jednak nie kończy, ponieważ pliki obiektowe są jedynie efektem skompilowania pojedynczych plików źródłowych (.cpp).
Zaraz po kompilatorze wkracza linker, który łączy (linkuje) wszystkie nasze pliki obiektowe, biblioteki itd. w jeden, cały plik wykonywalny. Linker jest trochę głupi, ponieważ linker nie potrafi czytać kodu - on czyta tylko pliki obiektowe wygenerowane przez kompilator. W ich środku nie ma kodu (takiego C++owego), ale jest kod binarny i symbole.
Wyobraźmy sobie przykładowy, zmyślony proces kompilacji, w którym kompilator zamienia nasz przykładowy kod:
#include <iostream>
int sum(int from, int to);
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
w
symbol int_main:
cout "Suma od 1 do 10 wynosi"
result = call int_sum_int_int
cout result
cout '\n'
symbol int_main oznaczałby deklarację symbolu, następnie w środku znajdują się instrukcje w naszym mainie.
Zauważ, że znajduje się tam tylko i wyłącznie odwołanie do int_sum_int_int.
Tak mniej więcej wygląda to w pliku obiektowym, tyle, że trochę bardziej strasznie i magicznie. Wywołanie funkcji w naszym programie, to po po prostu przejście pod odpowiedni adres w pliku wykonywalnym, wykonanie kodu, a potem powrócenie (potencjalnie zapisując wartość zwróconą gdzieś).
Linker podczas czytania takiego pliku obiektowego próbuje znaleźć adres symbolu int_sum_int_int,
żeby można go potem było wstawić do pliku wykonywalnego - jednak nie może!, takiego symbolu w ogóle nie ma w naszym pliku obiektowym,
ponieważ nie napisaliśmy definicji.
Właśnie z tego powodu dostajemy błąd. Dla porównania spójrzmy na inną, hipotetyczną sytuację, w której kod jest poprawny:
#include <iostream>
int sum(int from, int to);
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
Kompilator w naszym przykładzie zamieni to na:
symbol int_main:
cout "Suma od 1 do 10 wynosi"
result = call int_sum_int_int
cout result
cout '\n'
symbol int_sum_int_int:
// kod
Linker czytając taki plik może odnaleźć adres naszej funkcji, wziąć go i wsadzić w miejsce call int_sum_int_int.
Wszystko kompiluje się poprawnie, linkuje się poprawnie i wykonuje się poprawnie.
Wiele definicji
Weźmy pod lupę taki kod:
#include <iostream>
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
int main()
{
std::cout << "Suma od 1 do 10 wynosi: " << sum(1, 10) << '\n';
}
int sum(int from, int to)
{
int result = 0;
for (int i = from; i <= to; i++)
result += i;
return result;
}
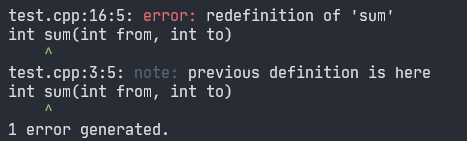
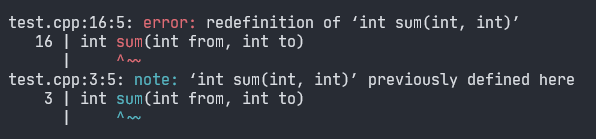
Programista przez przypadek zdefiniował tutaj funkcję sum dwa razy.
Jak wyżej zostało wspomniane - jest to złamanie zasady ODR (ang. One Definition Rule).
W programie jest dozwolona tylko jedna definicja funkcji, ponieważ kompilator nie będzie zgadywać która akurat
jest poprawna, a wiele definicji może oznaczać błąd programisty.
🔴 Treść błędu
- CLANG
- GCC
- MSVC

Niezapisanie typu zwracanego
Czasami możemy zobaczyć kod pokroju:
main()
{
...
}
Widzimy tutaj funkcję główną main bez typu zwracanego.
Jest to absolutnie niepoprawny kod. Niektóre kompilatory mogą go zaakceptować i skompilowąć (w ramach rozszerzenia), aczkolwiek kod ten jest nielegalny.
Jest to zaszłość z C (notabene - zapis ten usunięto również w C, w standardzie C99), która, jeśli typ nie zostaje podany, automatycznie zakłada typ zwracany int.
Fukcjonalność ta jest nazywana "implicit int" i nie powinno się na niej w ogóle polegać.
🔴 Treść błędu
- CLANG
- GCC
- MSVC



Zauważ, że kompilator gcc w tym przypadku wystosował tylko i wyłącznie ostrzeżenie, zamiast błędu. Jak już wcześniej pisałem, jest to dlatego, że niektóre kompilatory mogą zezwalać na pewne rzeczy w kodzie, które technicznie, wg standardu C++ nie powinny się skompilować, w ramach rozszerzeń. Jak widać, gcc pozwala na niezapisywanie typu zwracanego, jednak daje nam ostrzeżenie, że nie jest to poprawny kod.
Na rozszerzeniach nie powinno się polegać, ponieważ sprawiają one, że nasz kod jest zależny od kompilatora, mniej przenośny i nie ma w 100% gwarantowanego działania.
Zwrócenie wartości innego typu niż oczekiwany
Jak poznaliśmy w tej lekcji, funkcje albo mogą zwracać wartości określonego typu, albo nie zwracać nic. W obu przypadkach, musimy albo zwrócić wartość tego typu, albo nie zwracać nic, inaczej dostaniemy błąd.
- 🔢 Funkcja coś zwracająca
- ⚪ Funkcja nic nie zwracająca
int foo()
{
return "?";
}
int main()
{
foo();
}
W przypadku funkcji która zwraca wartość innego typu, niż zadeklarowany typ zwracany (tutaj zwracamy napis, kiedy typ zwracany to liczba), dostaniemy błąd wewnątrz funkcji który mówi o niekompatybilnych typach, czasem ta informacja może być dość nieczytelna.
🔴 Treść błędu
- CLANG
- GCC
- MSVC



void foo()
{
return 5;
}
int main()
{
foo();
}
W przypadku zwracania jakiejkolwiek wartości z funkcji, która deklaruje, że żadnej nie zwraca (tutaj zwracamy liczbę, mimo, że mówimy, ze nie zwracamy nic), dostaniemy czytelny błąd o tym, że zwracamy z funkcji, która nie powinna nic zwracać.
🔴 Treść błędu



Niezwracanie wartości
Mówiliśmy wcześniej w lekcji o tablicach o tzw. niezdefiniowanym zachowaniu. Niezdefiniowane zachowanie nie tyczy się jednak tylko wychodzenia poza tablicę. Tak naprawdę zachowań, która uważa się za niezdefiniowane jest bardzo wiele. Jednym z nich jest niezwracanie wartości z funkcji, która deklaruje, że zwraca wartość jakiegoś typu, np.:
#include <iostream>
int fun()
{}
int main()
{
std::cout << fun();
}
Jak już dowiedzieliśmy się wcześniej - niezdefiniowane zachowanie to czarna magia i to co się stanie zależy od kompilatora, systemu, fazy księżyca i innych różnych mistycznych stworzeń.
Bardzo możliwe, że dostaniemy ostrzeżenie o braku zwróconej wartości, jednak kod tak czy siak się skompiluje. W przypadku niezdefiniowanego zachowania kompilator może, ale nie musi wystosować błąd.
Po przetestowaniu różnych narzędzi zauważamy następujące rezultaty:
- CLANG
- GCC
- MSVC
Skompilowany przez clang po uruchomieniu sprawia, że niektóre powłoki pokazują błąd "Illegal instruction" lub nie pokazuje nic:
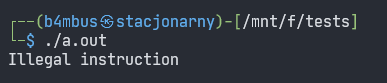


Program skompilowany przez gcc po uruchomieniu nie pokazuje żadnego błędu, a proces zwraca kod 0 - czyli wykonanie pomyślne.
W przypadku kompilatora MSVC, dostajemy jednak błąd, że foo musi zwracać wartość:
error C4716: 'foo': must return a value
🖼 Ilustracja błędu:

Dodatkowe informacje
Dedukcja typu i "wiodący typ zwracany"
Tak samo jak możemy użyć słówka kluczowego auto w przypadku zmiennych, aby typ zmiennej został wydedukowany przez kompilator,
możemy również zamiast typu zwracanego funkcji dać auto, aby typ zwracanej wartości był wydedukowany, np.
auto println(std::string msg) {
std::cout << msg << '\n';
}
Tutaj typ zwracany zostaje wydedukowany do void, bowiem nie zwracamy żadnej wartości.
auto clamp(int value, int low, int high) {
if(value < low) return low;
if(value > high) return high;
return value;
}
W przypadku funkcji wyżej, typ zwracanej wartości to int.
clampclamp to funkcja często używana np. w gamedevie, aby upewnić się, że gracz znajduje się w pewnym ustalonym przedziale koordynatów na mapie.
Bierze wartość oraz przedział w postaci dwóch kolejnych argumentów o tym samym typie.
Jej zadaniem jest upewnienie się, że dana wartość nie przekracza przedziału z żadnej ze stron.
Jeśli wartość jest większa od górnej wartości, zwracana jest górna wartość:
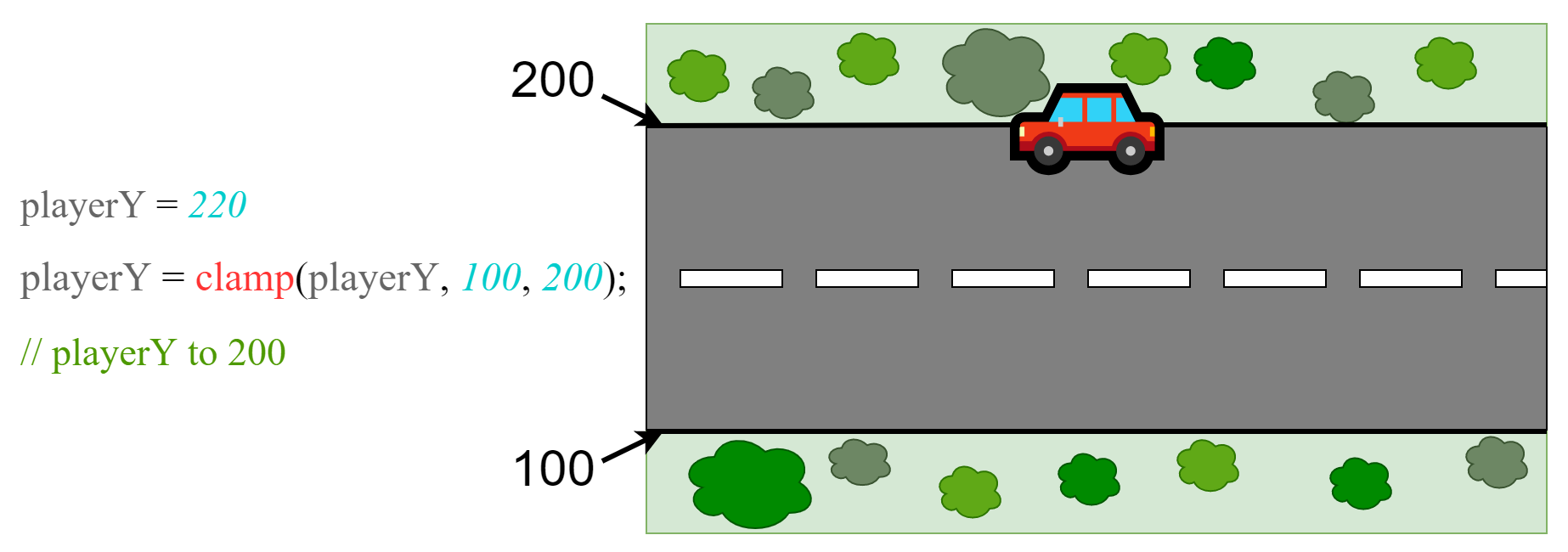
Jeśli wartość jest jest mniejsza od dolnej wartości, zwracana jest dolna wartość:
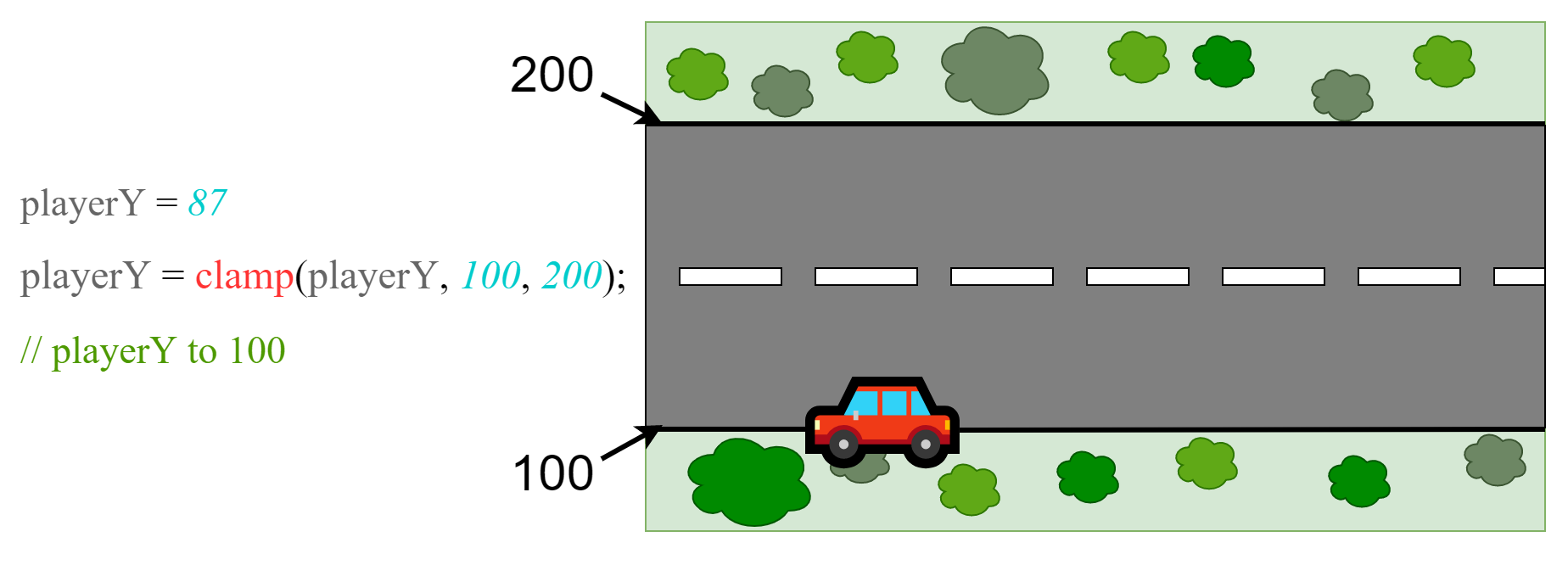
W przeciwnym wypadku zwracana jest oryginalna wartość:
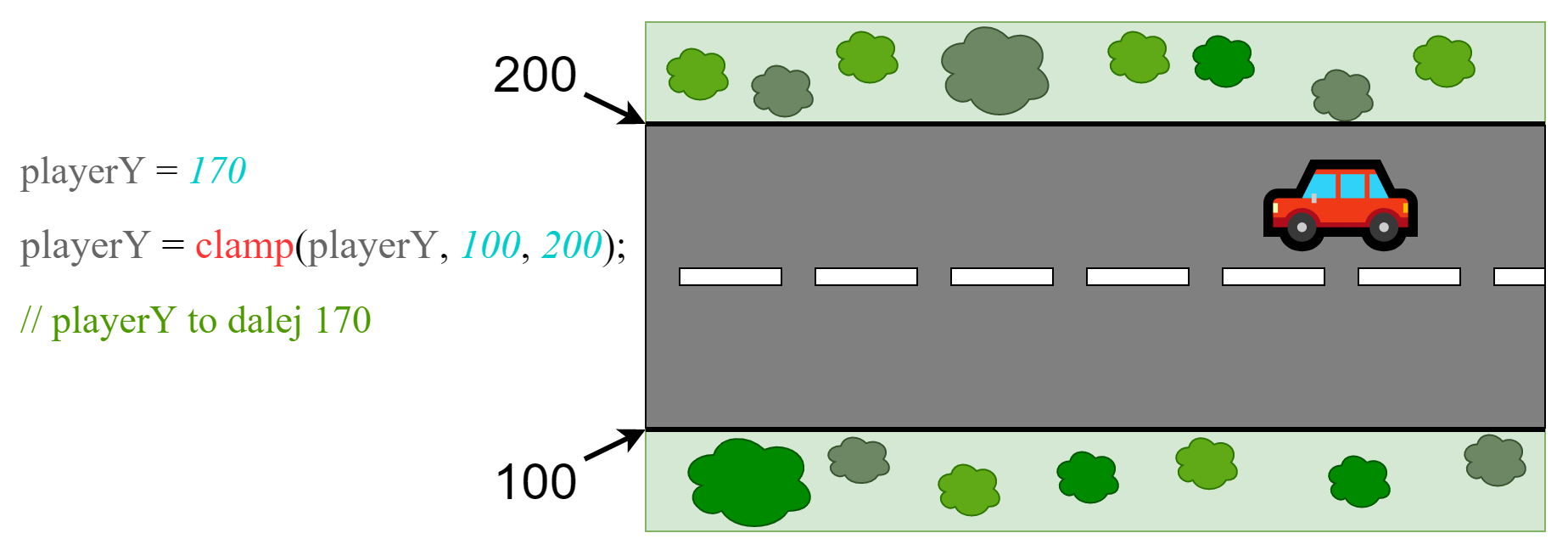
Oczywiście w prawdziwej grze przy próbie przekroczenia poprawnych koordynatów akcja ich "clampowania" dzieje się tak szybko, że gracz nie ma nawet szansy zobaczyć, że wyszedł poza ustalone granice, po prostu nie może przejechać dalej.
W C++ nie musimy jej również pisać sami, w standardzie C++ znajdziemy funkcję std::clamp znajdującą się w nagłówku <algorithm>.
Problemem z dedukcją wartości jest to, że nie może ona być stosowana zawsze. Główne dwa scenariusze w których nie można stosować dedukcji typu zwracanego, to:
- Deklaracja funkcji przed jej definicją
- Rekurencja
O rekurencji dowiemy się kiedy indziej, jednak co do pierwszego punktu - gdy wywołujemy funkcję, kompilator musi znać wszystkie informacje o niej (nazwa, typ zwracany, argumenty).
Dedukcja typu zwracanego funkcji, jest możliwa dopiero po poznaniu ciała, definicji funkcji. Dlatego nie możemy użyć funkcji która została zadeklarowana z auto zamiast typu,
przed poznaniem definicji.
- ❌ Źle
- ✔ Dobrze
#include <iostream>
auto clamp(int value, int low, int high);
int main()
{
int playerY = 300;
auto clampedPlayerY = clamp(playerY, 100, 200); // typ zwracany nie jest tutaj jeszcze znany, błąd kompilacji
std::cout << clampedPlayerY << '\n';
}
auto clamp(int value, int low, int high)
{
if(value < low) return low;
if(value > high) return high;
return value;
}
#include <iostream>
auto clamp(int value, int low, int high)
{
if(value < low) return low;
if(value > high) return high;
return value;
}
int main()
{
int playerY = 300;
auto clampedPlayerY = clamp(playerY, 100, 200); // ok, typ zwracany jest znany
std::cout << clampedPlayerY << '\n';
}
Co ciekawe - C++ pozwala również na podanie typu w tym przypadku. Typ ten zapisujemy po strzałce, po deklaracji:
auto clamp(int value, int low, int high) -> int;
Jest to równoważne z:
int clamp(int value, int low, int high);
Notacja ta nazywa się z angielskiego trailing return type (wiodący typ zwracany).
Wiele innych języków używa podobnej składni, funkcje w tego typu notacji lepiej układają się pod sobą + są przypadki, kiedy typ zwracany zależy od typu parametru i wtedy trzeba użyć tej notacji.
Dobre praktyki
Dobra nazwa
Każda funkcja to pewien kod, który reprezentuje jedną logiczną operację. Nawyk dobrego nazywania funkcji powinien wejść w krew jak najszybciej, albowiem nazwy funkcji bardzo wpływają na czytelność kodu oraz kilka innych kluczowych jego aspektów.
Funkcja ma cel, który ma wykonywać, oraz implementację. Celem będzie np. policzenie równania kwadratowego, implementacją będzie sam kod, który będzie to wykonywać. Nazwa funkcji powinna odwzorowywać cel, nie implementację.
Głównym tego powodem jest to, że osoby wywołującą funkcję nie powinno interesować to w jaki sposób dana funkcja coś robi, tylko co robi. Drugi powód jest taki, że implementacja funkcji może się zmienić na przestrzeni rozwoju naszej aplikacji. Możemy zmieniać, naprawiać, dodawać i usuwać kod w środku (czyt. zmieniać implementację), ale o ile cel naszej funkcji dalej jest taki sam - nazwa pozostanie taka sama, co również pozwoli uniknąć tzw. złamania API (ang. API breakage).
Podstawowe pytanie - czym jest API? API, z angielskiego to Aplication Programming Interface.
Brzmi tajemniczo, ale przyjrzyjmy się temu trochę bliżej. Czym jest interfejs?
Wyobraźmy sobie pralkę. Pralka ma w środku skomplikowaną maszynerię, dużo elementów mechanicznych i elektronicznych, których celem jest finalnie wypranie naszych ubrań. My do komunikacji z pralką używamy przycisków, pokrętł, ekranów dotykowych, etc. To właśnie jest interfejs. Pozwala on na interakcję z pralką.
W przypadku programowania, API to również wszystko co pozwala na interakcję. Funkcja ma nazwę, parametry i typ zwracany. Weźmy dla przykładu taką funkcję:
void assignPlayerToTeam(std::string player)
{
// ...
}
Mamy tutaj funkcję assignPlayerToTeam.
W część jej interfejsu wchodzi jej nazwa (assignPlayerToTeam), typy jej parametrów (std::string) oraz jej typ zwracany (void).
Dlaczego łamanie API jest takie niebezpieczne?
Cóż, wyobraź sobie, że masz całą halę pełną pralek oraz po jednym robocie obsługującym każdą pralkę (pralka - funkcja, robot - kod korzystający z funkcji).
std::vector<float> washingMachine3000(std::string button, int knob)
{
// ...
}
Każdy robot jest dokładnie nauczony gdzie znajduje się jaka pralka, gdzie na tej pralce są jakie przyciski i w jakiej kolejności jakie akcje należy wykonać, aby doprowadzić do udanego wyprania ubrań.
std::vector<float> result = washingMachine3000("click", 123);
Wyobraź sobie teraz, że producent tych pralek nagle podmienia swoją czarodziejską różdżką wszystkie stare pralki na nowszy model. Można powiedzieć - powód do radości, w końcu nowszy model, pralki są szybsze, pobierają mniej wody i prądu, super. Nie do końca - nowy model pralek ma zmieniony interfejs - poprzestawianie guziki, brak niektórych pokrętł, zastąpione innych elementów dotykowymi panelami (zmieniona nazwa funkcji, inny typ zwracany, inne typy czy kolejność argumentów).
std::string washingMachine5000(float touchPanel, std::string button)
{
// ...
}
...
std::vector<float> result = washingMachine3000("click", 123); // oops!
Nagle każdy robot (kod korzystający z funkcji) szaleje i wybucha, ponieważ każdy robot jest nauczony korzystać z określonej pralki (funkcji) w określony sposób, jednak interfejs się zmienił, więc nic nie działa tak jak powinno.
Łamanie API to bardzo często sytuacja której chcemy uniknąć, ponieważ sprawia dużo kłopotów programistom utrzymującym kod, który korzysta z naszych funkcji. Nie zawsze jest to możliwe i wtedy stosuje się różnego rodzaju techniki, które powiadamiają programistów o przyszłym złamaniu obietnicy, którą jest interfejs.
Jedna logiczna operacja
Funkcje powinny wykonywać tylko i wyłącznie jedną logiczną operację, powinny realizować tylko jeden cel na raz. Wydzielanie jak najmniejszych kawałków kodu do funkcji niesie za sobą cały szereg korzyści:
-
:::info Zwiększenie reużywalności funkcji Jeśli funkcje wykonują tylko jedną logiczną operację, to jest większa szansa, że będzie można je wykorzystać w wielu miejscach, w porównaniu do funkcji, które robią wiele rzeczy.
Jeśli mamy funkcję, która usuwa spacje z przodu i z tyłu napisu, to nie użyjemy jej tam, gdzie będziemy potrzebować usunąć tylko spacje z przodu. Za to jeśli będziemy mieć dwie funkcje - jedną usuwającą spacje z przodu, a drugą z tyłu, to nie dość, że będziemy mogli zaimplementować funkcję, która usuwa znaki jednocześnie i z przodu i tyłu na podstawie tamtych dwóch, to jeszcze będzie mieli do dyspozycji dwie inne, bardziej specyficzne, usuwające tyko z przodu lub z tyłu. :::
-
:::info Większa szansa na optymalizacje Nie będziemy się wgłębiać w powody dlaczego tak jest. Warto po prostu zapamiętać, że kompilator potrafi lepiej zoptymalizować kod, który używa małych, dobrze podzielonych funkcji, w przeciwieństwie do takiego, w którym funkcje są duże i nie wykonują małej ilości operacji. :::
-
:::info Łatwiejszy w analizie kod Małe funkcje są zazwyczaj łatwiejsze w analizie niż duże funkcje. Kod korzystający z małych, dobrze nazwanych funkcji również jest zazwyczaj łatwiejszy w analizie, niż taki, który korzysta z funkcji, które ukrywają dużo rzeczy przed programistą.
Jeśli funkcja nazywa się
stringToInt, to programista czytając zapisstringToInt("3113")spodziewa się tylko i wyłącznie zwrócenia przez tę funkcję liczby o wartości 3113, żadnego wypisywania ani żadnych innych akcji w tle. Wszystko co powinno być widoczne, będzie w takim układzie widoczne. ::: -
:::info Funkcje łatwiejsze w testowaniu Testowanie nie jest tematem dla początkujących, aczkolwiek zdecydowanie jest aspektem ważnym w pracy programisty. Testowanie polega na niczym innym niż sprawdzaniu, czy kod napisany przez programistę jest poprawny (tzn. czy spełnia ustalone założenia).
Testowanie funkcji, które same za siebie mówią co robią, są podzielone na logiczne operacje i nie mają efektów ubocznych, jest znacznie prostsze, niż testowanie potworów o niebotycznych wielkościach, rozwiązujących wszystkie problemy świata. :::
-
:::info Funkcje łatwiejsze w nazywaniu Tak jak już wcześniej powiedzieliśmy - nazwa funkcji powinna odzwierciedlać operację, którą ta funkcja wykonuje. Funkcje wykonujące pojedyncze operacje nazwać jest dość łatwo i szybko.
W przypadku funkcji, które nie podążają za tą dobrą praktyką, musimy się namyśleć jak oddać istotę funkcji, która robi wiele rzeczy na raz, co jest oczywiście trudniejsze. :::